Policy Information
Dataset之MNIST:MNIST(手写数字图片识别+ubyte.gz文件)数据集的下载(基于python语言根据爬虫技术自动下载MNIST数据集)
目录
1、主文件 mnist_download_main.py文件
代码打包地址:mnist数据集下载的完整代码——mnist_download_main.rar
- 1、读取数据集
- MNIST数据集大约12MB,如果没在指定的路径中找到就会自动下载。
- from mnist import MNIST
- data = MNIST(data_dir="data/MNIST/") 它由70,000张图像和对应的标签(图像的类别)组成。数据集分成三份互相独立的子集。本教程中只用训练集和测试集。
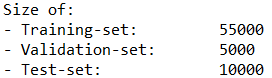
- print("Size of:")
- print("- Training-set:\t\t{}".format(data.num_train))
- print("- Validation-set:\t{}".format(data.num_val))
- print("- Test-set:\t\t{}".format(data.num_test))
- Downloads the MNIST data-set for recognizing hand-written digits.
- Implemented in Python 3.6
- Usage:
- 1) Create a new object instance: data = MNIST(data_dir="data/MNIST/")
- This automatically downloads the files to the given dir.
- 2) Use the training-set as data.x_train, data.y_train and data.y_train_cls
- 3) Get random batches of training data using data.random_batch()
- 4) Use the test-set as data.x_test, data.y_test and data.y_test_cls
- This file is part of the TensorFlow Tutorials available at:
- https://github.com/Hvass-Labs/TensorFlow-Tutorials
- Published under the MIT License. See the file LICENSE for details.
- Copyright 2016-18 by Magnus Erik Hvass Pedersen
-
- import numpy as np
- import gzip
- import os
- from dataset import one_hot_encoded
- from download import download
-
-
- Base URL for downloading the data-files from the internet.
- base_url = "https://storage.googleapis.com/cvdf-datasets/mnist/"
-
- Filenames for the data-set.
- filename_x_train = "train-images-idx3-ubyte.gz"
- filename_y_train = "train-labels-idx1-ubyte.gz"
- filename_x_test = "t10k-images-idx3-ubyte.gz"
- filename_y_test = "t10k-labels-idx1-ubyte.gz"
-
-
-
- class MNIST:
- """
- The MNIST data-set for recognizing hand-written digits.
- This automatically downloads the data-files if they do
- not already exist in the local data_dir.
- Note: Pixel-values are floats between 0.0 and 1.0.
- """
-
- The images are 28 pixels in each dimension.
- img_size = 28
-
- The images are stored in one-dimensional arrays of this length.
- img_size_flat = img_size * img_size
-
- Tuple with height and width of images used to reshape arrays.
- img_shape = (img_size, img_size)
-
- Number of colour channels for the images: 1 channel for gray-scale.
- num_channels = 1
-
- Tuple with height, width and depth used to reshape arrays.
- This is used for reshaping in Keras.
- img_shape_full = (img_size, img_size, num_channels)
-
- Number of classes, one class for each of 10 digits.
- num_classes = 10
-
- def __init__(self, data_dir="data/MNIST/"):
- """
- Load the MNIST data-set. Automatically downloads the files
- if they do not already exist locally.
- :param data_dir: Base-directory for downloading files.
- """
-
- Copy args to self.
- self.data_dir = data_dir
-
- Number of images in each sub-set.
- self.num_train = 55000
- self.num_val = 5000
- self.num_test = 10000
-
- Download / load the training-set.
- x_train = self._load_images(filename=filename_x_train)
- y_train_cls = self._load_cls(filename=filename_y_train)
-
- Split the training-set into train / validation.
- Pixel-values are converted from ints between 0 and 255
- to floats between 0.0 and 1.0.
- self.x_train = x_train[0:self.num_train] / 255.0
- self.x_val = x_train[self.num_train:] / 255.0
- self.y_train_cls = y_train_cls[0:self.num_train]
- self.y_val_cls = y_train_cls[self.num_train:]
-
- Download / load the test-set.
- self.x_test = self._load_images(filename=filename_x_test) / 255.0
- self.y_test_cls = self._load_cls(filename=filename_y_test)
-
- Convert the class-numbers from bytes to ints as that is needed
- some places in TensorFlow.
- self.y_train_cls = self.y_train_cls.astype(np.int)
- self.y_val_cls = self.y_val_cls.astype(np.int)
- self.y_test_cls = self.y_test_cls.astype(np.int)
-
- Convert the integer class-numbers into one-hot encoded arrays.
- self.y_train = one_hot_encoded(class_numbers=self.y_train_cls,
- num_classes=self.num_classes)
- self.y_val = one_hot_encoded(class_numbers=self.y_val_cls,
- num_classes=self.num_classes)
- self.y_test = one_hot_encoded(class_numbers=self.y_test_cls,
- num_classes=self.num_classes)
-
- def _load_data(self, filename, offset):
- """
- Load the data in the given file. Automatically downloads the file
- if it does not already exist in the data_dir.
- :param filename: Name of the data-file.
- :param offset: Start offset in bytes when reading the data-file.
- :return: The data as a numpy array.
- """
-
- Download the file from the internet if it does not exist locally.
- download(base_url=base_url, filename=filename, download_dir=self.data_dir)
-
- Read the data-file.
- path = os.path.join(self.data_dir, filename)
- with gzip.open(path, 'rb') as f:
- data = np.frombuffer(f.read(), np.uint8, offset=offset)
-
- return data
-
- def _load_images(self, filename):
- """
- Load image-data from the given file.
- Automatically downloads the file if it does not exist locally.
- :param filename: Name of the data-file.
- :return: Numpy array.
- """
-
- Read the data as one long array of bytes.
- data = self._load_data(filename=filename, offset=16)
-
- Reshape to 2-dim array with shape (num_images, img_size_flat).
- images_flat = data.reshape(-1, self.img_size_flat)
-
- return images_flat
-
- def _load_cls(self, filename):
- """
- Load class-numbers from the given file.
- Automatically downloads the file if it does not exist locally.
- :param filename: Name of the data-file.
- :return: Numpy array.
- """
- return self._load_data(filename=filename, offset=8)
-
- def random_batch(self, batch_size=32):
- """
- Create a random batch of training-data.
- :param batch_size: Number of images in the batch.
- :return: 3 numpy arrays (x, y, y_cls)
- """
-
- Create a random index into the training-set.
- idx = np.random.randint(low=0, high=self.num_train, size=batch_size)
-
- Use the index to lookup random training-data.
- x_batch = self.x_train[idx]
- y_batch = self.y_train[idx]
- y_batch_cls = self.y_train_cls[idx]
-
- return x_batch, y_batch, y_batch_cls
-
-
- Class for creating a data-set consisting of all files in a directory.
- Example usage is shown in the file knifey.py and Tutorial 09.
- Implemented in Python 3.5
- This file is part of the TensorFlow Tutorials available at:
- https://github.com/Hvass-Labs/TensorFlow-Tutorials
- Published under the MIT License. See the file LICENSE for details.
- Copyright 2016 by Magnus Erik Hvass Pedersen
-
- import numpy as np
- import os
- import shutil
- from cache import cache
-
-
-
- def one_hot_encoded(class_numbers, num_classes=None):
- """
- Generate the One-Hot encoded class-labels from an array of integers.
- For example, if class_number=2 and num_classes=4 then
- the one-hot encoded label is the float array: [0. 0. 1. 0.]
- :param class_numbers:
- Array of integers with class-numbers.
- Assume the integers are from zero to num_classes-1 inclusive.
- :param num_classes:
- Number of classes. If None then use max(class_numbers)+1.
- :return:
- 2-dim array of shape: [len(class_numbers), num_classes]
- """
-
- Find the number of classes if None is provided.
- Assumes the lowest class-number is zero.
- if num_classes is None:
- num_classes = np.max(class_numbers) + 1
-
- return np.eye(num_classes, dtype=float)[class_numbers]
-
-
-
-
- class DataSet:
- def __init__(self, in_dir, exts='.jpg'):
- """
- Create a data-set consisting of the filenames in the given directory
- and sub-dirs that match the given filename-extensions.
- For example, the knifey-spoony data-set (see knifey.py) has the
- following dir-structure:
- knifey-spoony/forky/
- knifey-spoony/knifey/
- knifey-spoony/spoony/
- knifey-spoony/forky/test/
- knifey-spoony/knifey/test/
- knifey-spoony/spoony/test/
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询





评论