Policy Information
ML之RS:基于用户的CF+LFM实现的推荐系统(基于相关度较高的用户实现电影推荐)
目录
- ML之RS:基于CF和LFM实现的推荐系统
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import time
- import warnings
- warnings.filterwarnings('ignore')
- np.random.seed(1)
-
- plt.style.use('ggplot')
- data = pd.read_csv('ml-20m/ratings_smaller.csv', index_col=0)
- movies = pd.read_csv('ml-20m/movies_smaller.csv')
-
- 1、导入数据集
- data = pd.read_csv('ml-latest-small/ratings.csv')
- movies = pd.read_csv('ml-latest-small/movies.csv')
- movies = movies.set_index('movieId')[['title', 'genres']]
-
- 2、观察数据集
- How many users?
- print (data.userId.nunique(), 'users')
-
- How many movies?
- print (data.movieId.nunique(), 'movies')
-
- How possible ratings?
- print (data.userId.nunique() * data.movieId.nunique(), 'possible ratings')
-
- How many do we have?
- print (len(data), 'ratings')
- print (100 * (float(len(data)) / (data.userId.nunique() * data.movieId.nunique())), '% of possible ratings')
-
-
-
- Number of ratings per users
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('userId').apply(lambda x: len(x)).values, bins=50)
- plt.xlabel("ratings")
- plt.ylabel("users")
- plt.title("Number of ratings per user")
- plt.show()
-
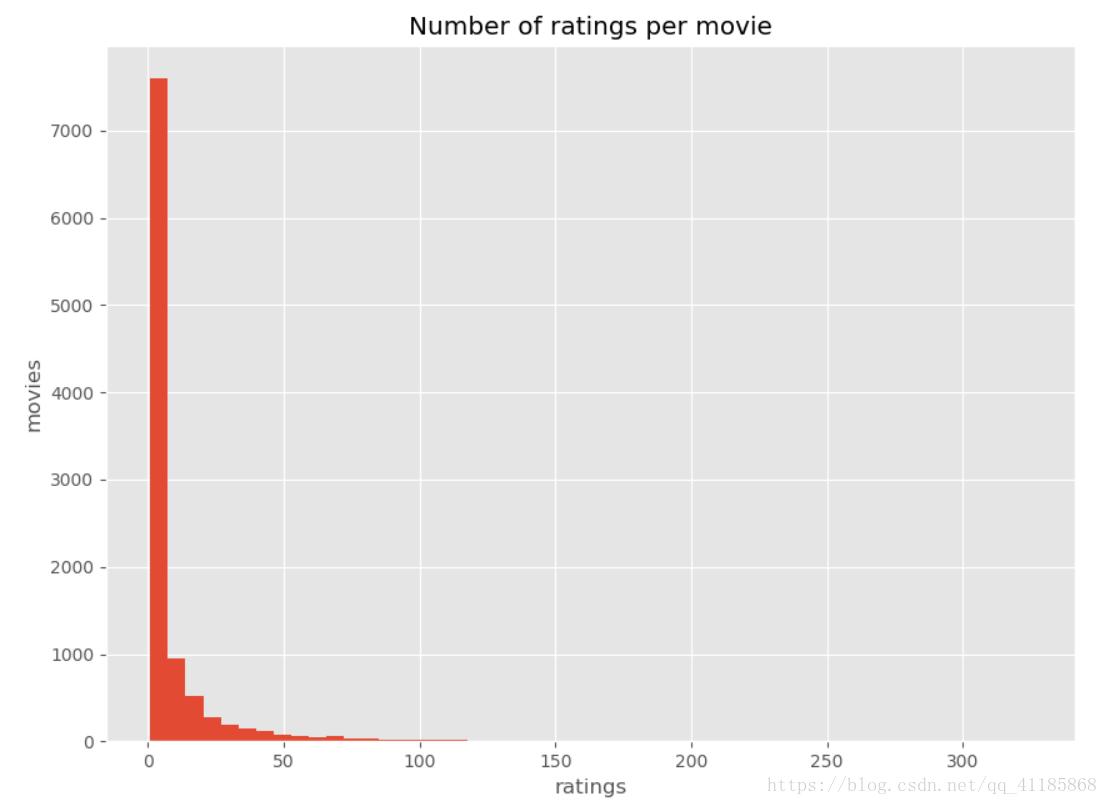
- Number of ratings per movie
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('movieId').apply(lambda x: len(x)).values, bins=50)
- plt.xlabel("ratings")
- plt.ylabel("movies")
- plt.title('Number of ratings per movie')
- plt.show()
-
- Ratings distribution评分分布
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.rating.values, bins=5)
- plt.xlabel("ratings")
- plt.ylabel("numbers")
- plt.title("Distribution of ratings")
- plt.show()
-
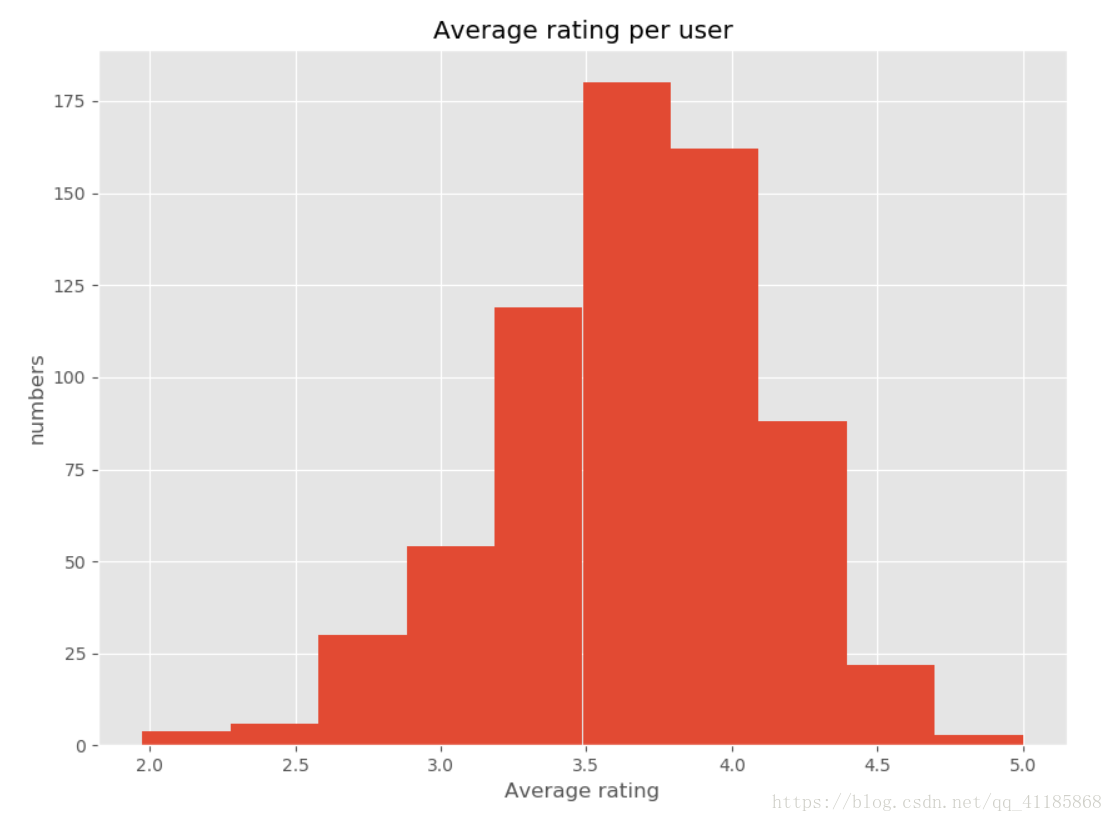
- Average rating per user
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('userId').rating.mean().values, bins=10)
- plt.xlabel("Average rating")
- plt.ylabel("numbers")
- plt.title("Average rating per user")
- plt.show()
-
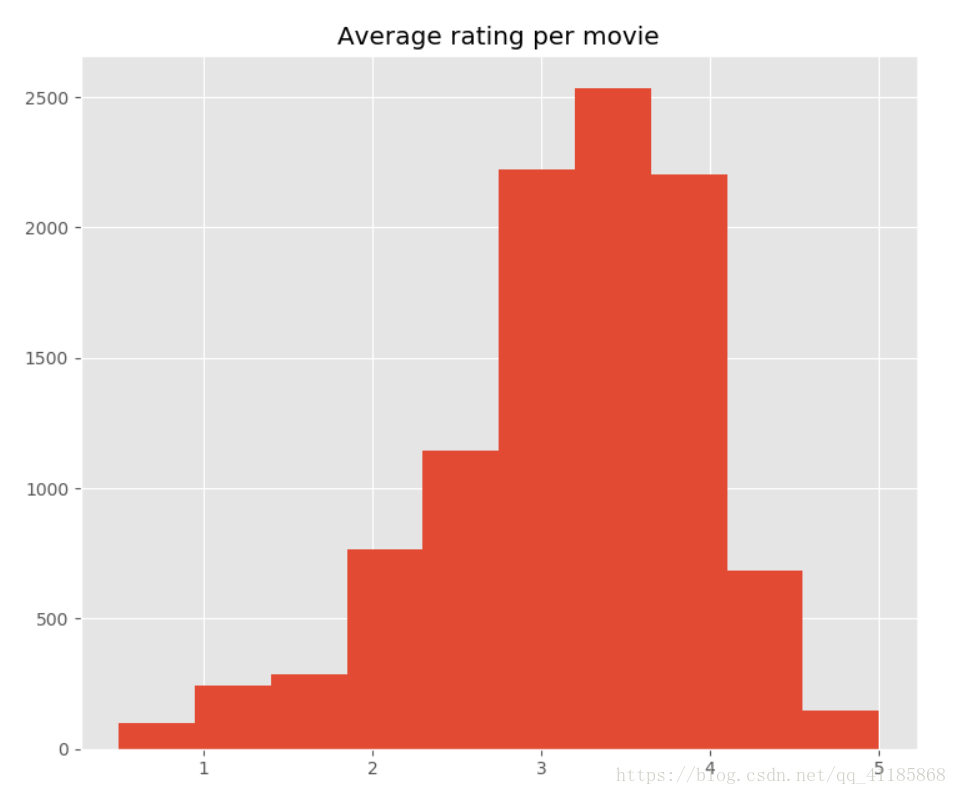
- Average rating per movie
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('movieId').rating.mean().values, bins=10)
- plt.title('Average rating per movie')
- plt.show()
-
- Top Movies,genres电影类型
- average_movie_rating = data.groupby('movieId').mean()
- top_movies = average_movie_rating.sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[top_movies.index.values],
- average_movie_rating.loc[top_movies.index.values].rating], axis=1)
-
- Robust Top Movies - Lets weight the average rating by the square root of number of ratings让平均评分进行加权数的平方根
- top_movies = data.groupby('movieId').apply(lambda x:len(x)**0.5 * x.mean()).sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[top_movies.index.values],
- average_movie_rating.loc[top_movies.index.values].rating], axis=1)
-
- controversial_movies = data.groupby('movieId').apply(lambda x:len(x)**0.25 * x.std()).sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[controversial_movies.index.values],
- average_movie_rating.loc[controversial_movies.index.values].rating], axis=1)
相关文章推荐
GitHub
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询






评论