Policy Information
Crawler:基于BeautifulSoup库+requests库实现爬取2018最新电影《后来的我们》热门短评
目录
- -*- coding: utf-8 -*-
-
- Py之Crawler:利用BeautifulSoup库实现爬取2018最新电影《后来的我们》热门短评
- import time
- import requests
- import csv
- from bs4 import BeautifulSoup
- head = 'https://movie.douban.com/subject/'
- middle = '/comments?start='
- zr_tail = '&limit=20&sort=new_score&status=P&percent_type='
- names = []
- header = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
- }
-
- zr_urls = ['最热']
- def createUrls():
- for j in range(1, 34, 2):
- name = names[j]
- print(name)
- for i in range(0, 100, 20):
- zr_urls.append(head + str(name) + middle + str(i) + zr_tail)
- print(zr_urls)得到某个电影短评地址(默认最热排序),如https://movie.douban.com/subject/27063335/comments?start=0&limit=20&sort=new_score&status=P&percent_type=
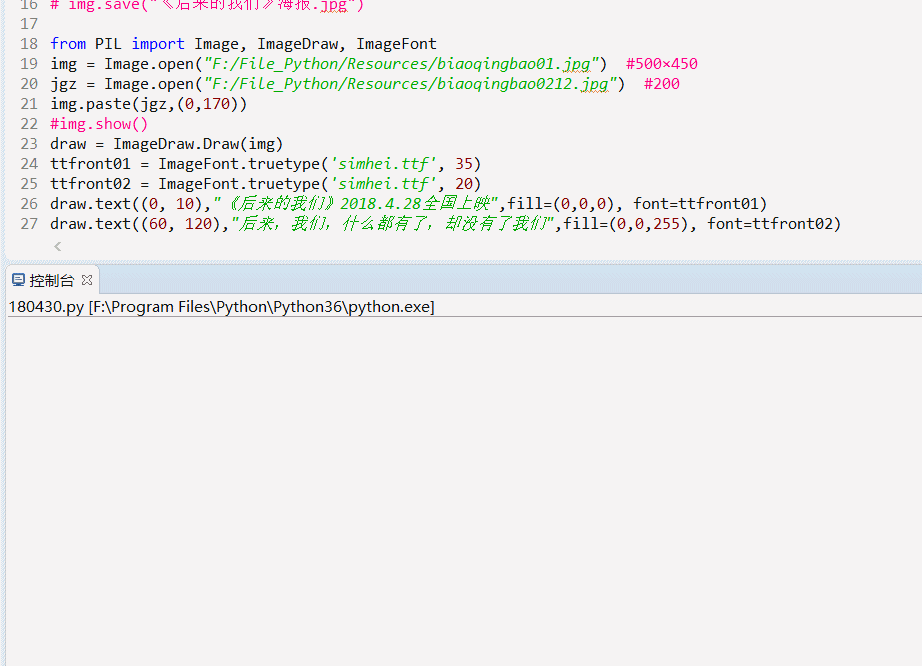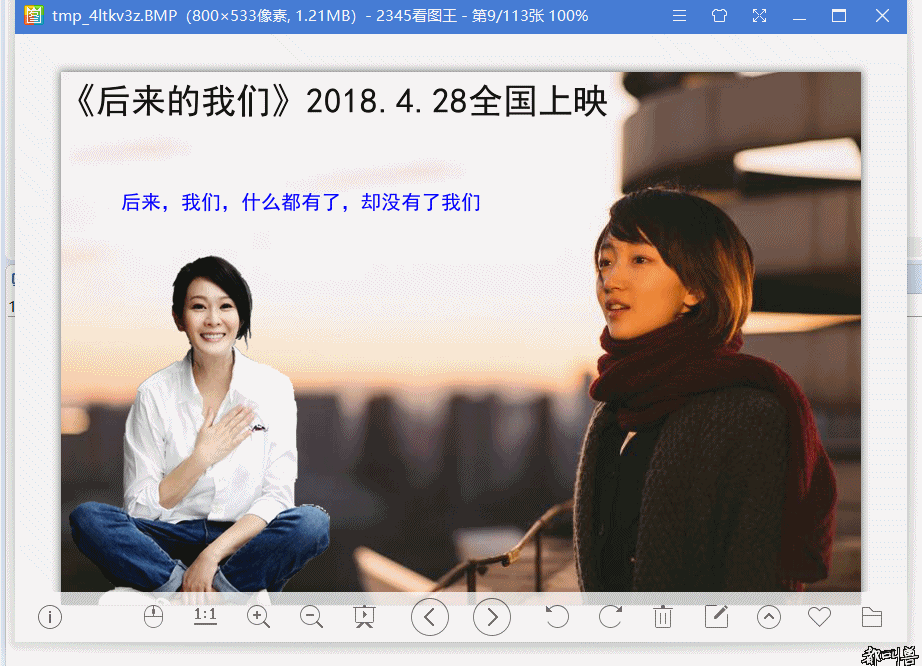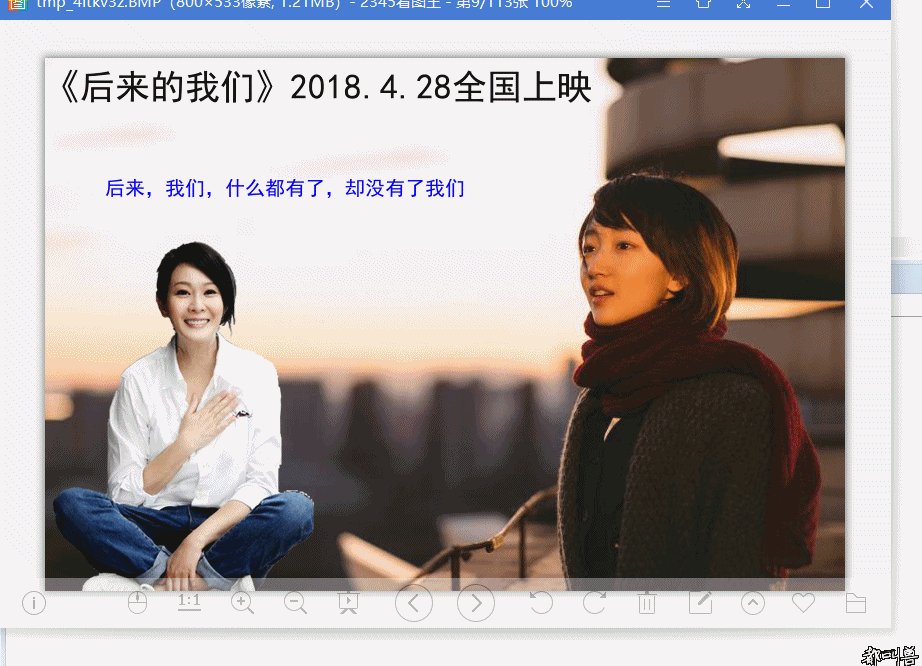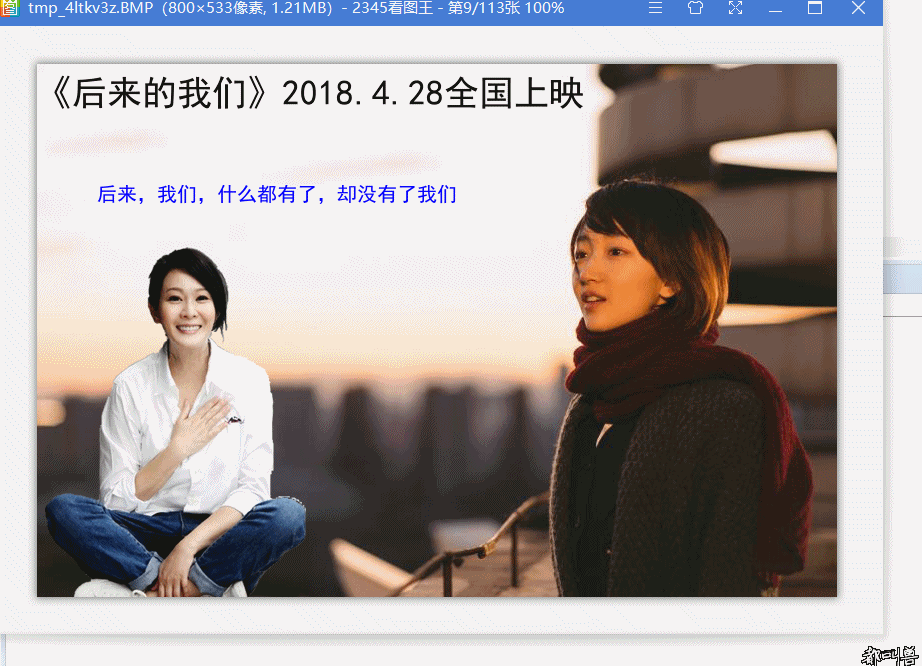
-
- def readName():
- with open('爬取电影名称.txt', mode='r', encoding='utf-8') as f:
- for i in f.readlines():
- i = i.strip('\n')
- names.append(i)
- print(names)
- readName()
- createUrls()
- get_comments(zr_urls) 传入zr_urls
完整代码,后续一周内即将公布!
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询






评论