Policy Information
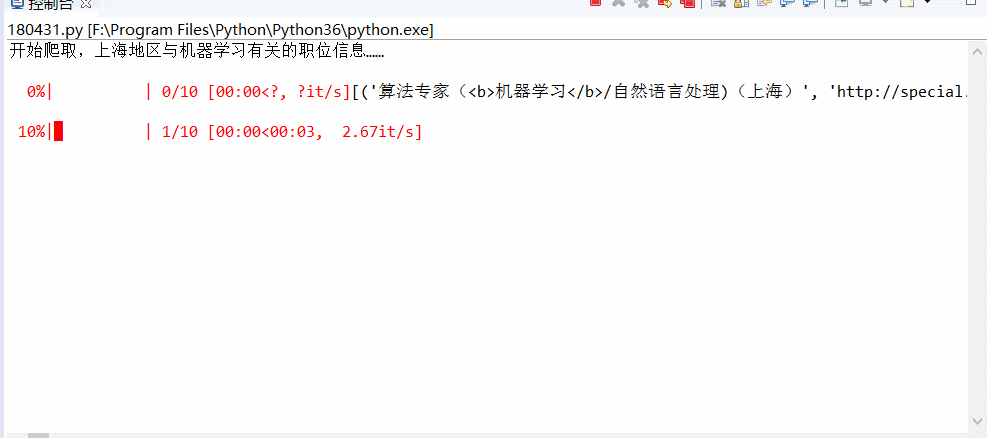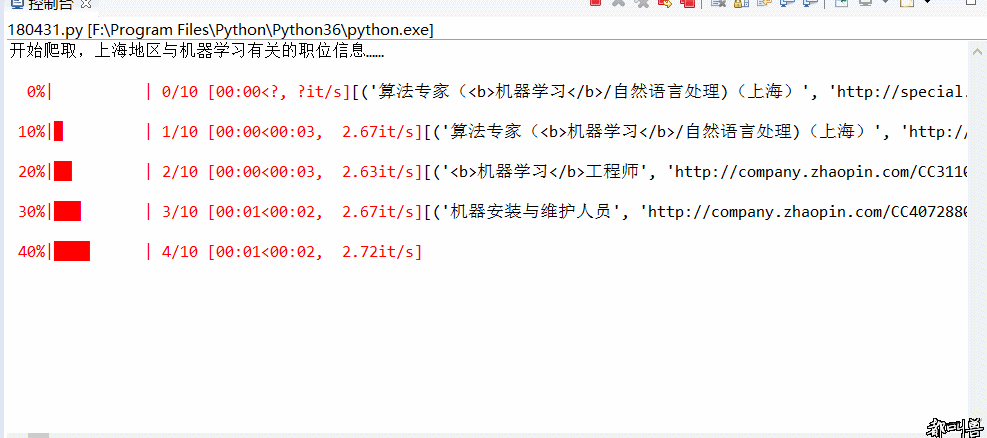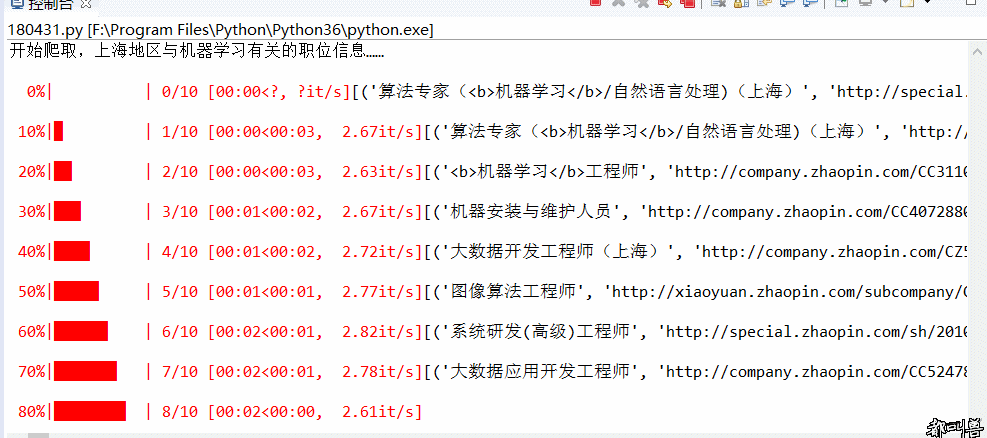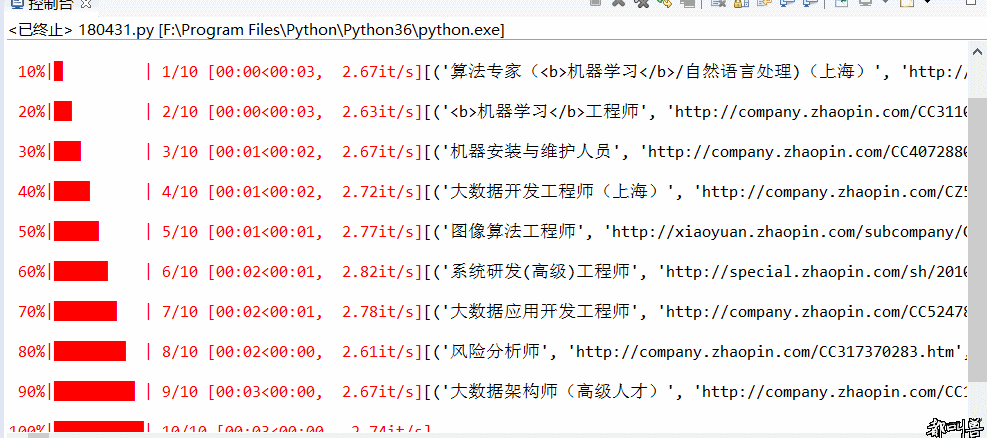
Crawler:基于urllib+requests库+伪装浏览器实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息(2018.4.30之前)并保存在csv文件内
目录
4月有31天?what?本人编程出错,感谢纠正!
- -*- coding: utf-8 -*-
-
- Py之Crawler:爬虫实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息并保存在csv文件内
-
- import re
- import csv
- import requests
- from tqdm import tqdm
- from urllib.parse import urlencode
- from requests.exceptions import RequestException
-
- def get_one_page(city, keyword, page):
- paras = {
- 'jl': city,
- 'kw': keyword,
- 'isadv': 0,
- 'isfilter': 1,
- 'p': page
- }
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
- 'Host': 'sou.zhaopin.com',
- 'Referer': 'https://www.zhaopin.com/',
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
- 'Accept-Encoding': 'gzip, deflate, br',
- 'Accept-Language': 'zh-CN,zh;q=0.9'
- }
-
- url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
- try:
- response = requests.get(url, headers=headers)
- if response.status_code == 200:
- return response.text
- return None
- except RequestException as e:
- return None
-
- def parse_one_page(html):
- pattern = re.compile('<a style=.*? >(.*?)</a>.*?'
- '<td class="gsmc"><a href="(.*?)" >(.*?)</a>.*?'
- '<td class="zwyx">(.*?)</td>', re.S)
- items = re.findall(pattern, html)
- print(items)
-
- for item in items: for循环的返回一个生成器
- job_name = item[0]
- job_name = job_name.replace('<b>', '')
- job_name = job_name.replace('</b>', '')
- yield { yield是一个关键词,类似return, 不同之处在于,yield返回的是一个生成器
- 'job': job_name,
- 'website': item[1],
- 'company': item[2],
- 'salary': item[3]
- }
- print(item)
-
- def write_csv_file(path, headers, rows):
- with open(path, 'a', encoding='gb18030', newline='') as f:
- f_csv = csv.DictWriter(f, headers)
- f_csv.writeheader()
- f_csv.writerows(rows)
-
- if __name__ == '__main__':
- main('上海', '机器学习', 10)
-
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询
 扫一扫加入群聊,了解更多平台咨询
扫一扫加入群聊,了解更多平台咨询











评论